Programming Python Technology Unraveling the Power of Python: A Beginner's Guide to Programming Brilliance In the vast landscape of programming languages,…
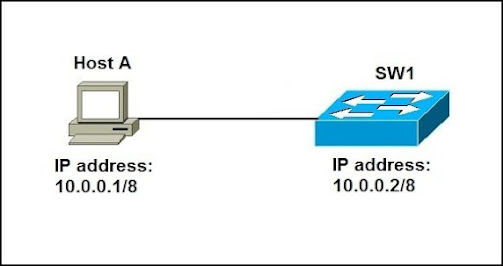
Computer Networks Practicals How to configure IP address for a computer? Aim: To configure the IP address for a computer c…
Computer Networks Practicals How to configure Wireless Access Point? Wireless Access Point Setup Instructions Here we …
JAVA Practicals Programming Technology trendings Implementation of packages and interfaces Aim: Implementation of packages and interfaces. I…
Programming Unraveling the Power of Python: A Beginner's Guide to Programming Brilliance In the vast landscape of programming languages,…
Artificial Intelligence Ridge and Lasso regression, Explained with Python. Ridge regression and Lasso regression are two bas…
anaconda What is Linear Regression and explained with example. Linear regression Linear regression is a supervi…
Computer Networks How to configure FTP on server 2003. Step to configure FTP on server 2003: Begin by op…
Computer Networks How to configure Wireless Access Point? Wireless Access Point Setup Instructions Here we …






.png)


